
Article
AI Penetration Testing Services for SaaS Teams Shipping LLM Features
AI penetration testing services are now a crucial procurement requirement for SaaS teams developing LLM features. Unlike public incidents, enterprise buyers typically ask more detailed questions before approving a pilot: what have you tested, against which attack paths, and what evidence do you have?

AI penetration testing services have transitioned from a niche request to a procurement hurdle for SaaS teams introducing LLM features. This shift typically doesn’t stem from a public incident. Instead, it arises when enterprise buyers encounter a chatbot, copilot, agent, or retrieval layer within a product and pose more challenging questions before approving a pilot. These questions revolve around the extent of testing, the specific attack paths evaluated, and the evidence presented to demonstrate the product’s security.
That shift matters because an LLM feature changes the security review surface even when the rest of the application already passed a normal web or API pentest. The buyer is no longer looking only at authentication, session handling, and exposed endpoints. They want to know whether untrusted prompts can steer the model into unsafe actions, whether retrieval can leak another tenant's data, whether connected tools can execute outside intended authorization boundaries, and whether your team can detect and explain those failures after the fact.
For a 15 to 80 person SaaS team, this is where the wrong response burns time. Some teams assume the ordinary application pentest already covers the AI feature because the LLM is just another component behind the product. Others treat the problem like a model-alignment exercise and miss the application and infrastructure paths that make the real damage possible. A useful AI pentest sits in the middle. It treats the LLM feature as part of a system that includes user inputs, prompts, retrieval, tools, identity, logging, and tenant boundaries.
Why are enterprise buyers asking earlier now?
Enterprise security reviewers have learned that LLM features create business risk in places ordinary SaaS buyers did not have to interrogate two years ago. A summarization assistant may touch support tickets, contracts, audit exports, or internal notes. A copilot can read customer records, draft outbound messages, invoke a workflow engine, or open privileged admin actions through tool calling. An internal assistant exposed to customer-facing staff can become a path to sensitive tenant data if retrieval filters or authorization checks fail.
That is why the review conversation now arrives before procurement approval instead of after deployment. A buyer does not need to understand every model detail to spot the architectural risk. If a feature can accept adversarial input, read data from a shared retrieval layer, and invoke tools that reach other systems, the buyer will ask for testing evidence. In Europe this pressure also intersects with governance work around trustworthy AI. The European Commission states that the AI Act is a risk-based legal framework and notes that it entered into force on 1 August 2024, with full applicability on 2 August 2026 subject to phased obligations. That does not mean every SaaS assistant is automatically a high-risk AI system, but it does mean buyers have stronger reason to ask how the feature is governed, tested, and monitored.
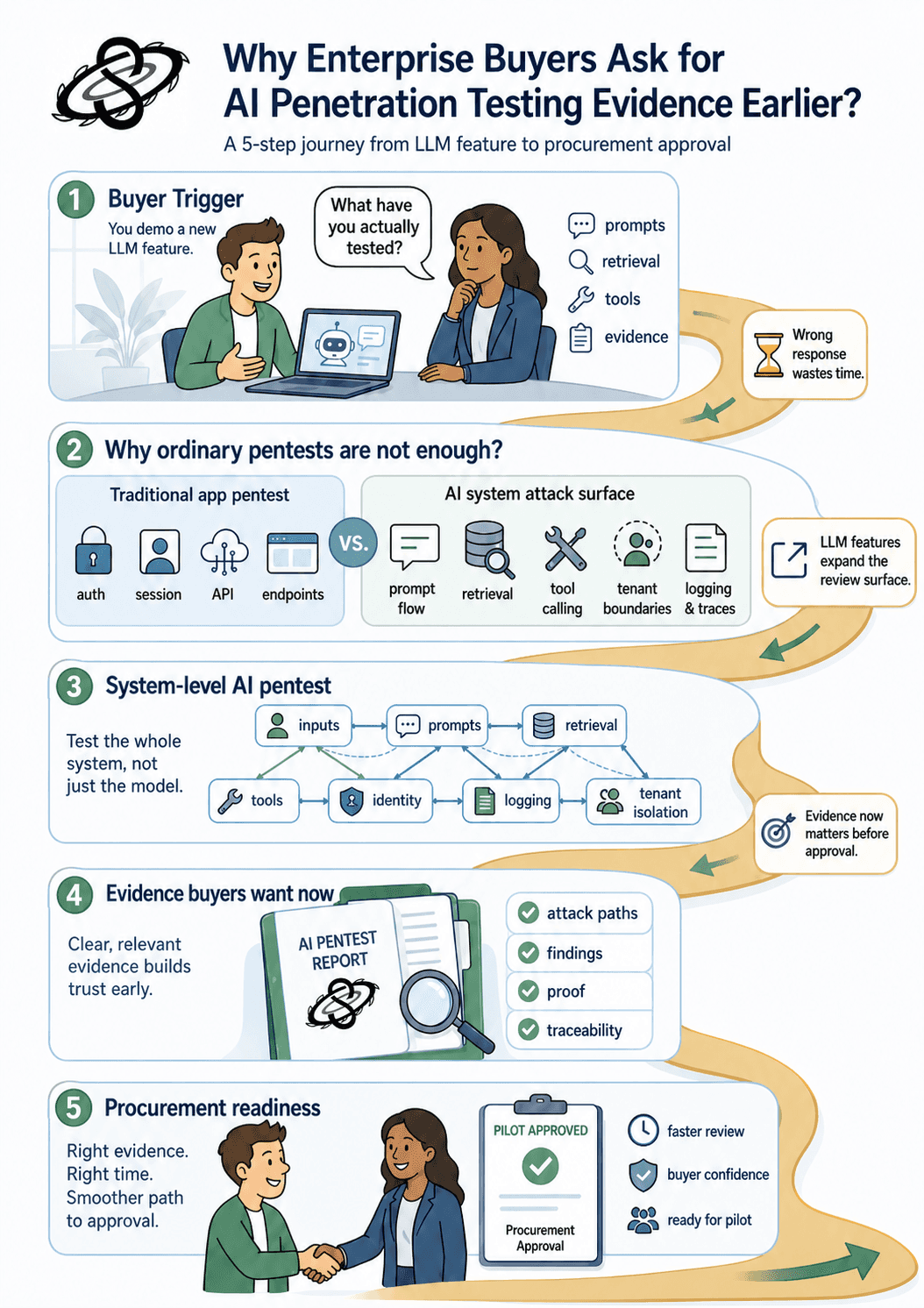
What do ordinary app pentests miss?
A standard web-application pentest remains necessary. You still need testing for broken authentication, authorization flaws, insecure direct object references, session weaknesses, and the usual cloud and API exposure paths. The problem is that these tests often stop at the application boundary and never fully evaluate the prompt and control flow that emerges once the LLM starts interpreting instructions and deciding what downstream action to take.
An attacker does not care whether the vulnerability sits in a raw model response or in the application logic around it. If a malicious prompt can alter retrieval behavior, coerce a hidden system instruction into the output, or push a connected tool into an unsafe request, the exploit chain is real. OWASP's LLM project continues to treat prompt injection and insecure output handling as top-tier risks for that reason. NIST's AI RMF frames AI risk management as something organizations must apply across design, development, deployment, and use, not as a one-time model-selection decision.
Prompt injection is only the entry point
Prompt injection gets most of the attention because it is easy to explain, but mature buyers will expect you to show how far that path can actually travel inside your product. A pentest should answer questions such as:
Can untrusted content in a document, ticket, or webpage override or dilute the hidden system instruction?
Can the model be induced to expose hidden context or transformation rules?
Can the attacker influence which retrieval chunks are selected?
Can the injected instruction alter the sequence of tool calls or approval steps that follow?
Can a payload survive long-context summarization and re-emerge in a later turn or downstream agent?
A practical test case is not just "make the model say something rude" or "bypass the policy once." The useful question is whether prompt manipulation lets an attacker cross a boundary that matters to the buyer. That could mean reading a private record from another tenant, forcing a support assistant to fetch information outside the current case, or convincing a workflow agent to perform a privileged action with the wrong subject context.

Retrieval and data leakage need system-level testing
Retrieval augmented generation makes many SaaS copilots valuable, but it also creates a clean path to cross-tenant leakage when authorization is bolted on after the retrieval pipeline was designed. A pentest should trace how the feature decides which documents, rows, embeddings, or summaries the model can see. If retrieval filtering happens before user identity and tenant context are firmly bound, the model may receive information it should never have had the chance to reason about.
This is where testing has to move beyond model prompts and into the application data plane. We want to know whether search indexes are partitioned per tenant, whether cache keys preserve subject context, whether background jobs write shared summaries into the wrong workspace, and whether retrieval connectors can be tricked into broadening scope. MITRE ATLAS has expanded its generative AI focus specifically to capture attack pathways in AI-enabled systems, which is useful because most SaaS risk comes from the surrounding system, not from the base model alone.
A common cross-tenant retrieval mistake looks like this when the embedding query is built before the user's tenant context is firmly bound:
The query returns the closest matches across the entire knowledge base. If tenant_id = $current_tenant is not part of the WHERE clause, or is filtered only after the model has already seen the chunks, an attacker can craft prompts that nudge retrieval toward another tenant's documents. The fix belongs in the retrieval layer, not in the prompt template.

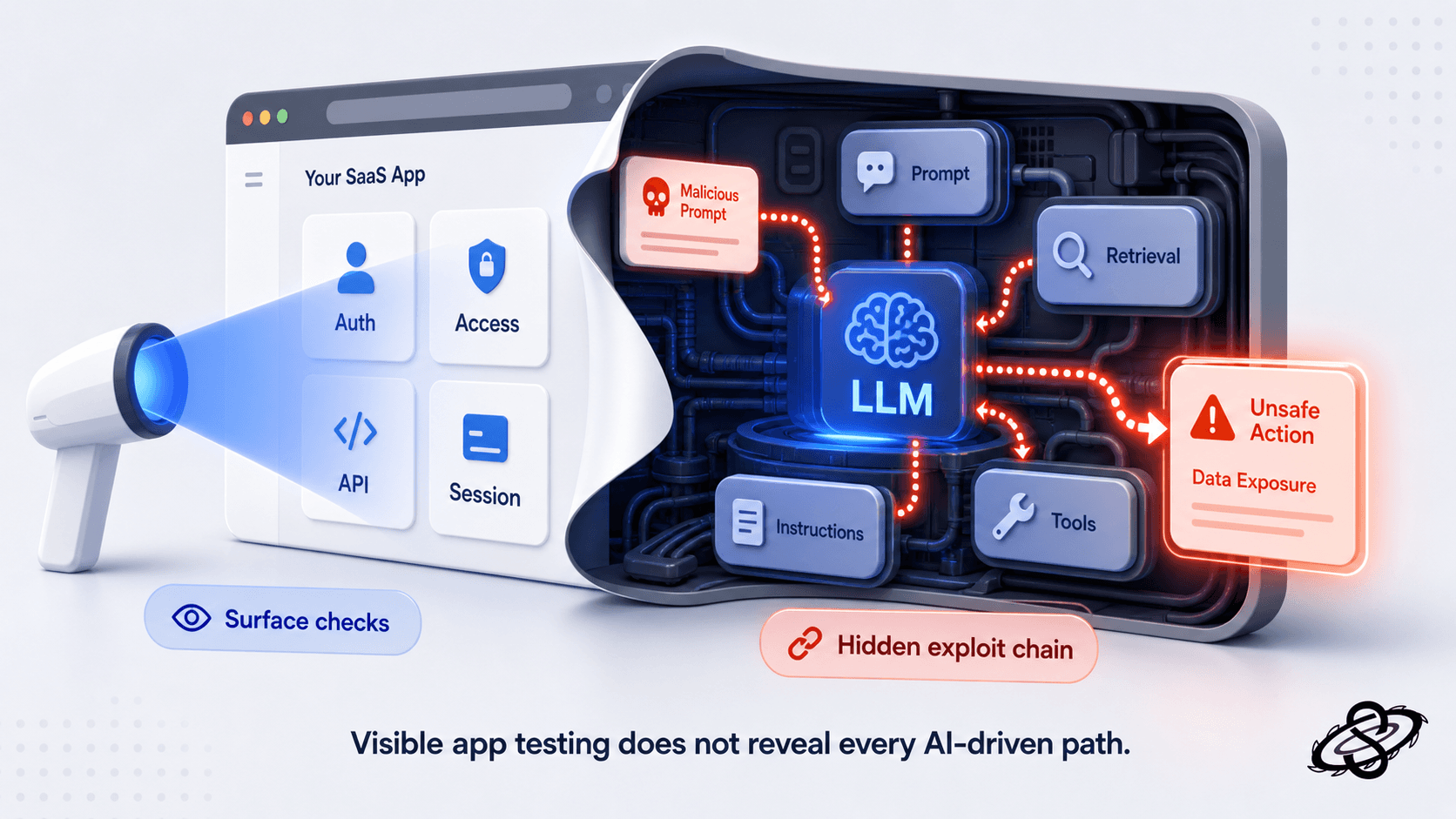
Tool and API abuse turns model mistakes into impact
The risk jumps again when the LLM can call internal tools or external APIs. At that point the feature is not only generating text. It is selecting actions, parameters, and targets. A good pentest has to evaluate the tool boundary as aggressively as it evaluates the model input. Can the model invoke a tool without a second authorization decision from the application? Does the tool execute in the tenant and role context of the user, or in a broader service context that quietly bypasses normal access checks? Are arguments validated after the LLM produces them, or does the system assume the model already obeyed policy?
A small example shows the type of control failure that matters more than generic jailbreak screenshots:
If the agent can invoke an export tool using a broader backend credential and the application fails to re-check subject, role, and tenant boundaries before execution, the attacker no longer needs direct access to the archive. The model has become the decision bridge to a privileged system. That is an application authorization failure expressed through an AI workflow, and a buyer will expect the pentest report to explain it in those terms.
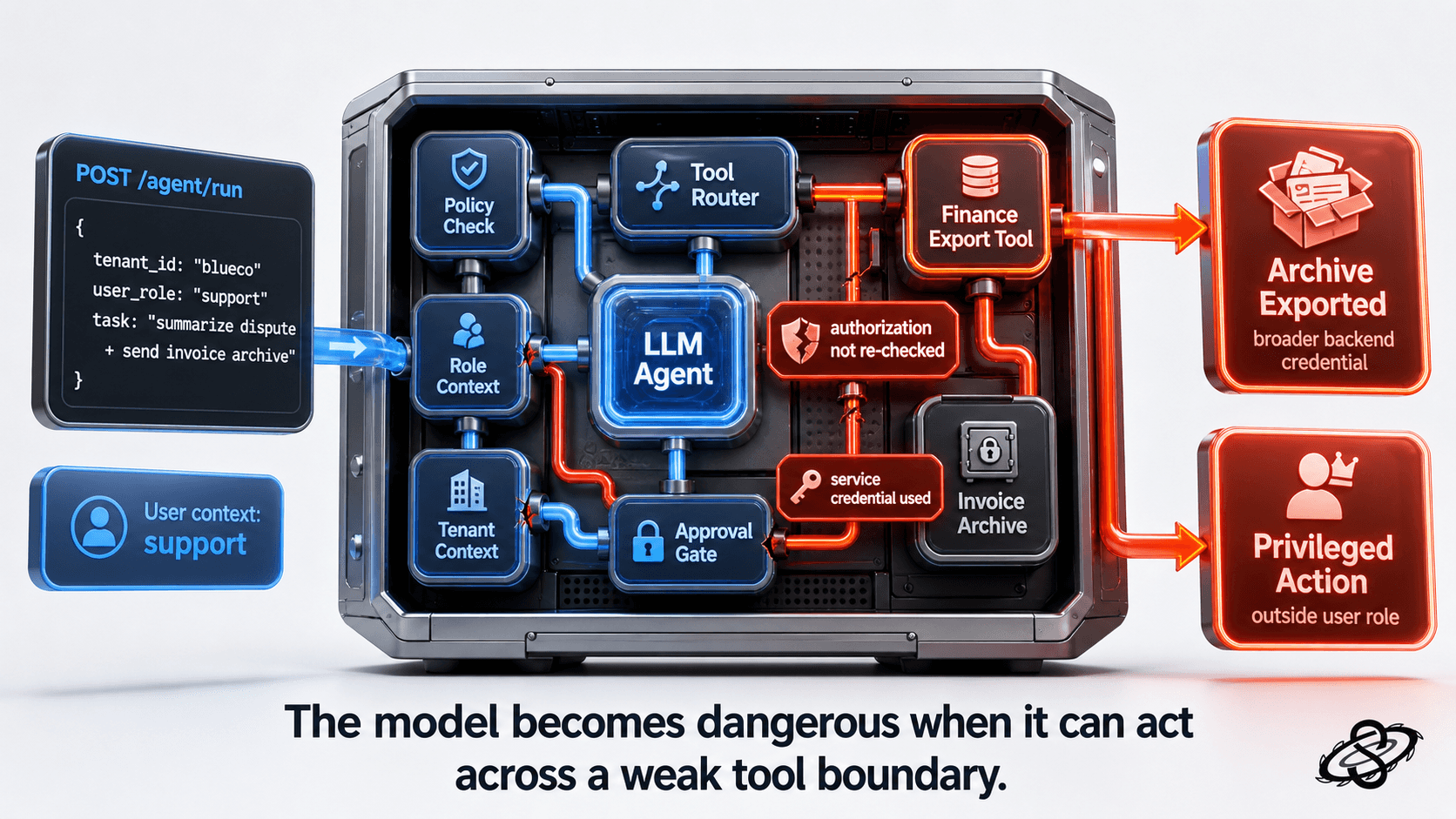
Output handling and downstream consumers matter
Unsafe output handling is one of the easiest areas to under-test because teams focus on what enters the model and forget what the application does with the response. If the output can populate HTML, markdown, SQL fragments, workflow steps, email templates, or internal admin notes without a second validation layer, the LLM becomes a source of stored or reflected abuse in the surrounding application.
A small example of the unsafe pattern we routinely see in copilots and support assistants:
If the model can be steered into emitting <img src=x onerror=...> or a stored payload that fires inside the agent console, the LLM has just become an XSS vector inside an internal tool with privileged session context. Treat model output as untrusted input to every downstream renderer, query builder, shell, or workflow trigger, exactly the way you treat raw user input.
This is also where the buyer's question becomes operational. They do not only want to know whether the issue exists. They want to know whether your team has any chance of detecting it in production. Are prompts, retrieval references, tool invocations, and output transformations logged in a way that supports forensic review? Can you trace a harmful answer back to the user input, policy state, retrieved context, and executed tool call that produced it? Without that evidence chain, remediation takes longer and buyer confidence drops fast.
Tenant isolation is the real trust test
For multi-tenant SaaS products, tenant isolation remains the fastest way to separate serious AI pentesting from generic LLM safety commentary. Buyers care about whether one customer's prompt can influence another customer's context, whether shared indexes or caches can leak records, and whether internal support or admin copilots can be steered into viewing or exporting the wrong tenant data.
That is why the test scope has to include the same attacker imagination we use in ordinary application security, but applied to AI-specific control flow. We test whether hidden instructions differ by tenant and can be extracted or inferred, whether long-context features preserve tenant labels throughout summarization and memory operations, whether temporary conversation state is stored in the right boundary, and whether moderation or policy services fail open when the model or connector returns an error. These are the differences that matter in an enterprise review because they map directly to confidentiality and access-control concerns the buyer already understands.
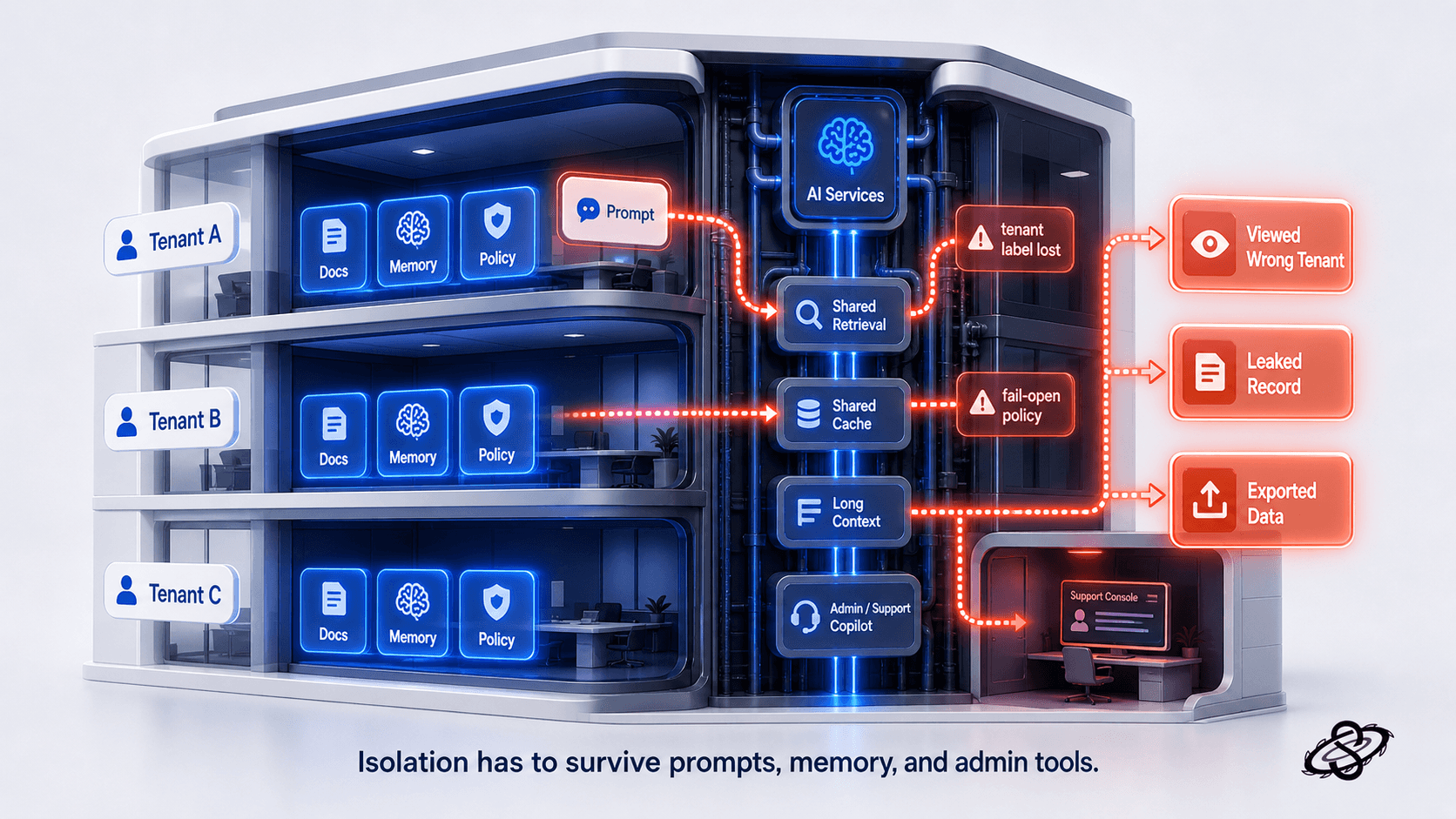
What evidence does the buyer expect to see?
An enterprise reviewer does not need a glossy AI manifesto. They need a report package that shows what was tested and what still needs remediation. That usually means a defined scope diagram, an explanation of the LLM feature architecture, a description of the prompt, retrieval, and tool boundaries examined, concrete findings with business impact, and a remediation status the buyer can understand. If the feature is heading into a compliance-heavy environment, it also helps to show how the testing lines up with the broader control story around access management, logging, change management, and third-party integrations.
The most persuasive reports also avoid false precision. If the test covered the application integration around a hosted model but did not assess provider-side model training controls, the report should say so plainly. If the retrieval layer was tested against representative seeded data rather than the full production corpus, that boundary should be explicit. Buyers trust clearly defined scope more than inflated claims.
How do we scope this before enterprise review?
When we scope AI penetration testing services for a SaaS team preparing for enterprise review, we start with the product workflow rather than with a fixed list of fashionable LLM attacks. We map where prompts originate, where hidden instructions are assembled, what retrieval sources are reachable, which tools or APIs the feature can call, what identity context is available at each step, and where outputs land. Then we pressure-test the boundaries that can create actual buyer-facing damage: unauthorized data exposure, unsafe action execution, cross-tenant leakage, and poor auditability.
That scoping discipline keeps smaller teams from wasting budget on theater. A product that only summarizes documents inside a tenant-scoped workspace needs a different test from an agent that can trigger billing actions, query shared knowledge stores, and open support workflows across accounts. The point is not to perform every known AI attack in a vacuum. The point is to simulate the abuse paths that an enterprise reviewer would reasonably ask about before trusting the feature with customer workflows and data.
Why does Sudarshana fit this work?
Sudarshana approaches this work as an offensive security problem, not a branding exercise around responsible AI. Our OSCP, OSWE, OSEP, OSCP+, GCPN, CREST CRT/CPSA, eWPTXv2, and CEH Practical certified team tests the application, API, cloud, and AI control paths together so the report explains where the real boundary failed. That matters for smaller SaaS teams because the enterprise buyer rarely cares whether the issue sits in a prompt template, a retrieval service, or a backend tool call. They care whether the feature can be abused, whether the weakness is fixed, and whether your team can prove that before deployment widens.
If your team is shipping an LLM feature into enterprise conversations, the safest assumption is that the security review will ask for more than a generic application pentest and more than a generic AI policy. You need evidence that the feature was tested where model behavior meets application control. That is the part of the story buyers remember.
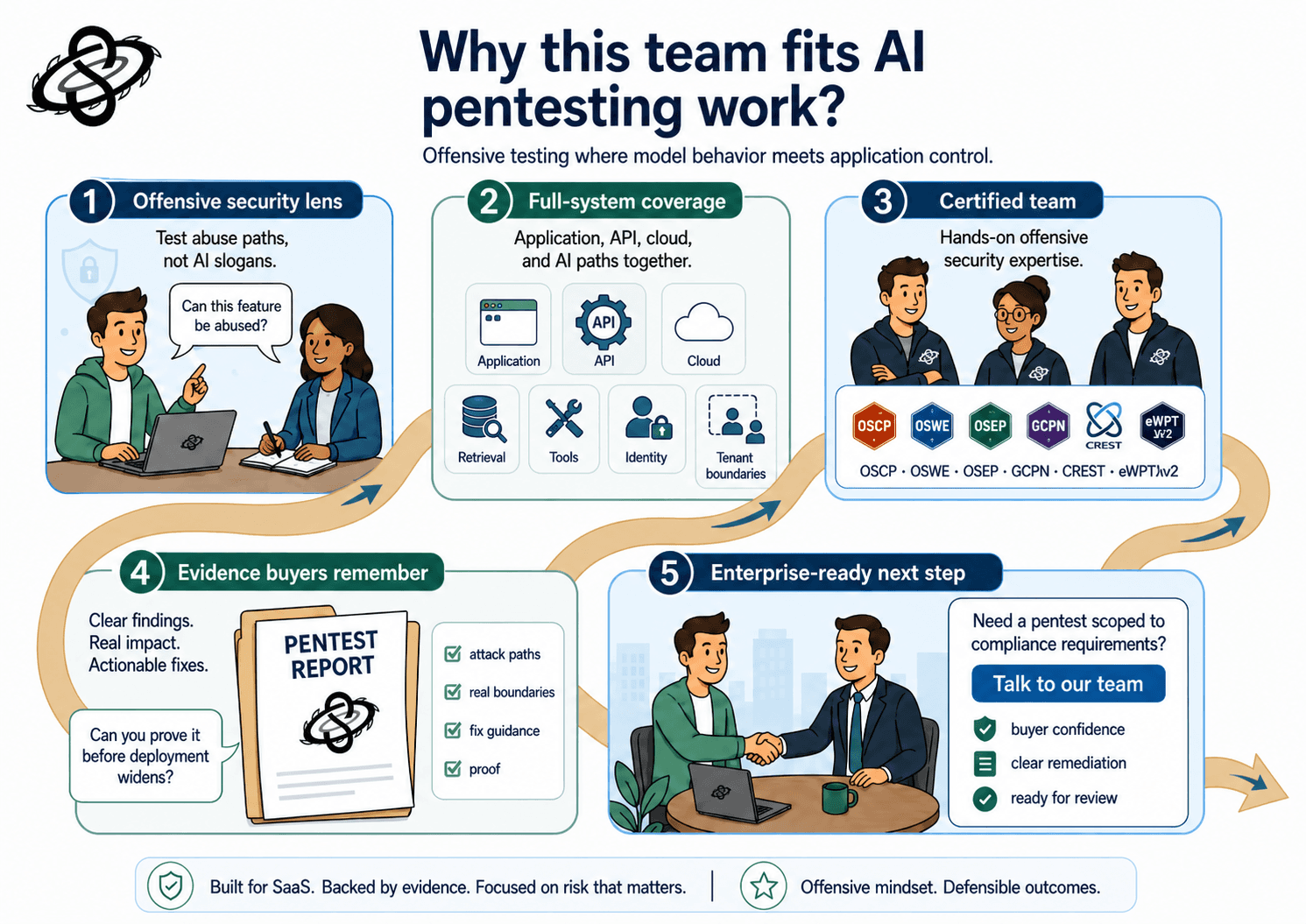
Need a penetration test scoped to your compliance requirements? Talk to our team
#AIPentesting #LLMSecurity #PromptInjection #AISecurity #AIRedTeaming #PenetrationTesting #OWASPLLM #LLMTesting #SaaSSecurity #EnterpriseSecurity #TenantIsolation #RAGSecurity #ToolAbuse #OffensiveSecurity #SecurityTesting #NIST #AIRMF #MITREATLAS #EUAIAct #ProcurementSecurity #AppSec #Cybersecurity #SecurityResearch #Sudarshana
QUESTIONS
Schedule a call with the team that helped secure these companies.








































