
Article
MCP Server Penetration Testing: Securing AI Agents With Tool-Use Access
MCP server penetration testing is key for teams deploying agents, copilots, and LLM workflows near production. Once models can discover tools, call them, and receive structured output via the Model Context Protocol, the attack surface expands beyond web apps, APIs, or cloud accounts. MCP becomes a new trust boundary, and skipping it risks data exposure, privilege misuse, or cross-system abuse. SaaS teams evaluating AI penetration testing should validate this protocol and tool-execution layer separately.

Teams deploying agents, copilots, and LLM workflows near production systems are increasingly turning to MCP server penetration testing. This shift stems from the fact that once a model can discover tools, call them, pass arguments, and receive structured output via the Model Context Protocol, the attack surface expands beyond traditional web apps, APIs, and cloud accounts. The MCP layer becomes a crucial trust boundary, and neglecting it can lead to approving AI features with exploitable paths to data exposure, privilege misuse, or cross-system abuse. For teams evaluating AI penetration testing services for SaaS LLM features, MCP introduces a protocol and tool-execution layer that warrants separate validation.
Why MCP changes the pentest scope?
MCP gives a model or agent a structured way to discover tools, read resources, and invoke actions in connected systems. At a security level, the trust boundary now runs across the AI client, the MCP client implementation, the MCP server, the authorization server, and the downstream APIs or data stores that actually do the work. A failure in any one of those layers can let the model do more than the user intended, see more than the user should access, or move data into places the organization never approved.
The current MCP documentation reflects this shift clearly. The authorization specification moved the protocol toward OAuth 2.1 resource-server behavior, the June 18, 2025 transport specification introduced explicit protocol-version handling for HTTP clients, and the security best-practices documentation calls out sandboxing, local-process risk, and confused-deputy problems as primary concerns.
A normal web or API penetration test still matters, but it does not fully answer the new questions. It may tell you whether the backend API has injection bugs or weak access control. It usually does not tell you whether tool descriptions can steer model behavior, whether hostile tool output becomes a second instruction channel, or whether discovery and token handling are correctly bound to audience and scope. That is why MCP needs its own test plan. The same buyer logic shows up in adjacent readiness questions such as whether SOC 2 is needed before the first enterprise customer: leadership is trying to defend an enterprise go-live decision with evidence, not assumptions.
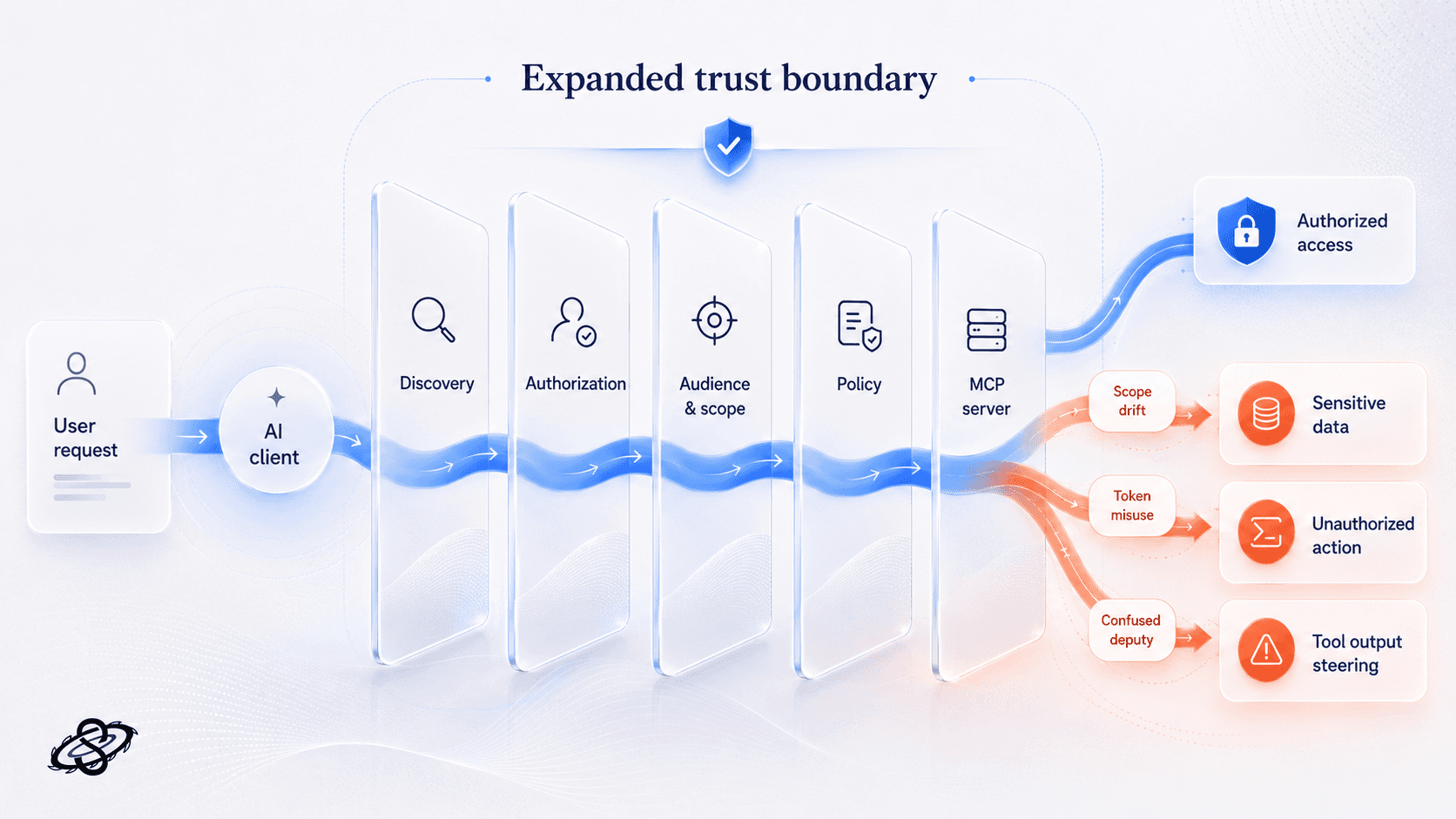
Threat classes against MCP servers
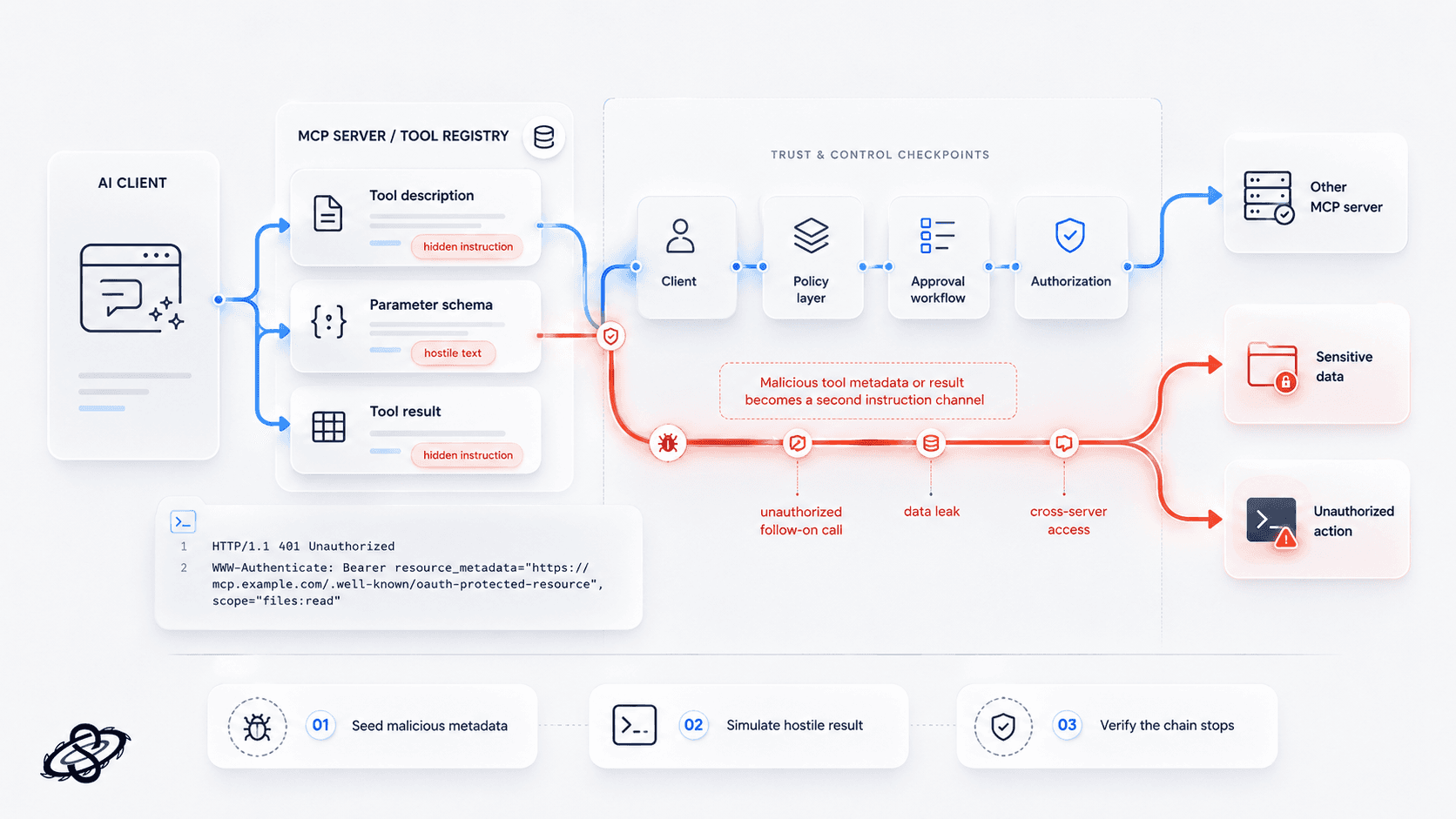
Tool poisoning and tool definition tampering
One of the most important MCP-specific attack classes is tool poisoning. OWASP documents this directly: malicious instructions can be hidden in tool descriptions, parameter schemas, or return values and used to manipulate model behavior. A real engagement should simulate hostile tool output and verify whether the client, policy layer, or approval workflow stops the chain before it turns into action.
What to test: seed malicious text into tool metadata and tool results, then confirm whether the agent attempts unauthorized follow-on calls, leaks data, or crosses into other servers.
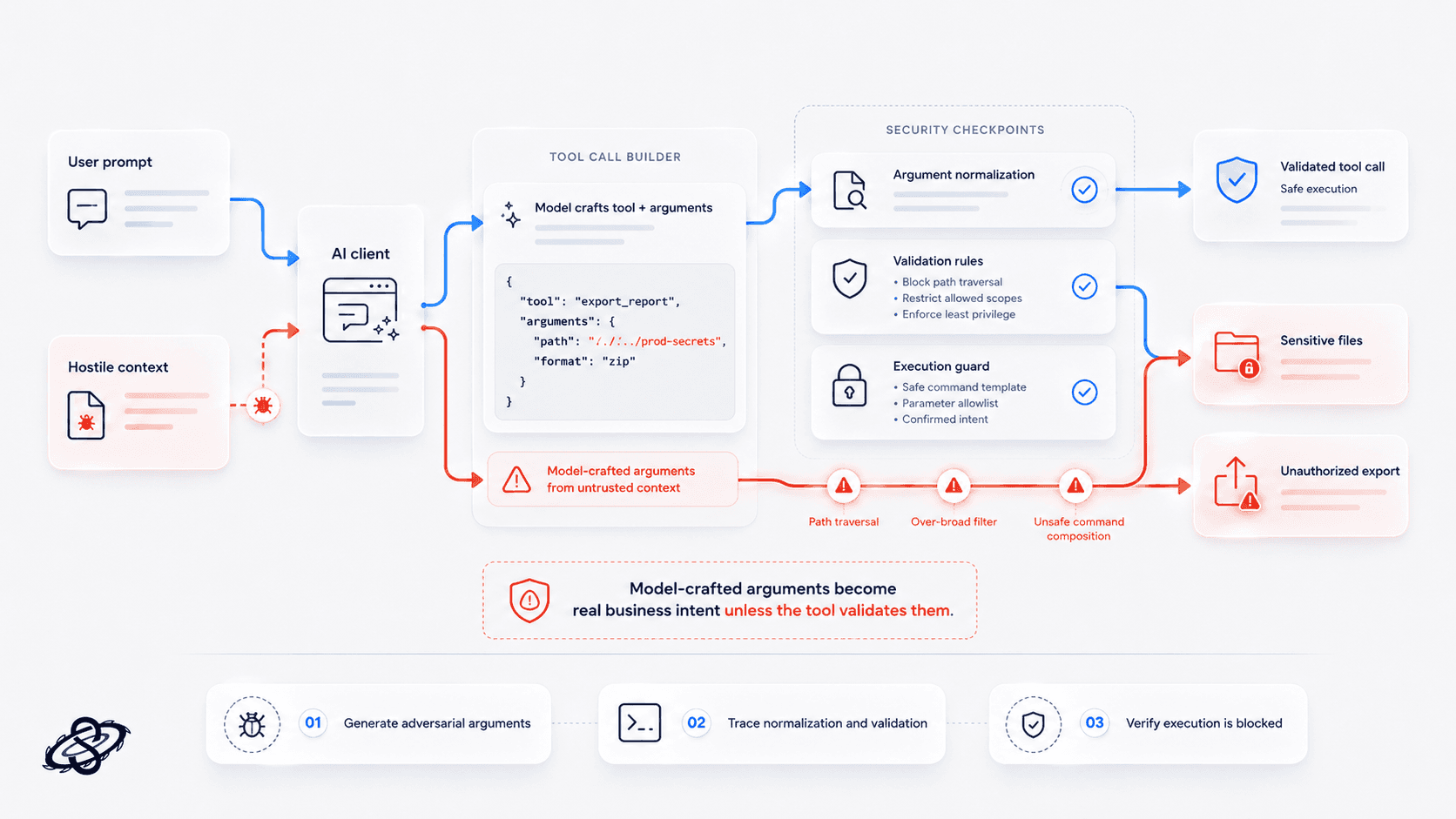
Argument injection through model-crafted tool calls
Argument injection is what happens when the model crafts tool parameters from untrusted content and the server treats them as valid business intent. If those arguments reach file operations, shell commands, query builders, or high-impact business APIs, a prompt-level trick can become a real security incident. A strong pentest traces how arguments are created, normalized, validated, and finally executed.
What to test: generate adversarial arguments from user prompts and hostile context, then verify whether tool-side validation blocks traversal, injection, over-broad filters, and unsafe command composition.
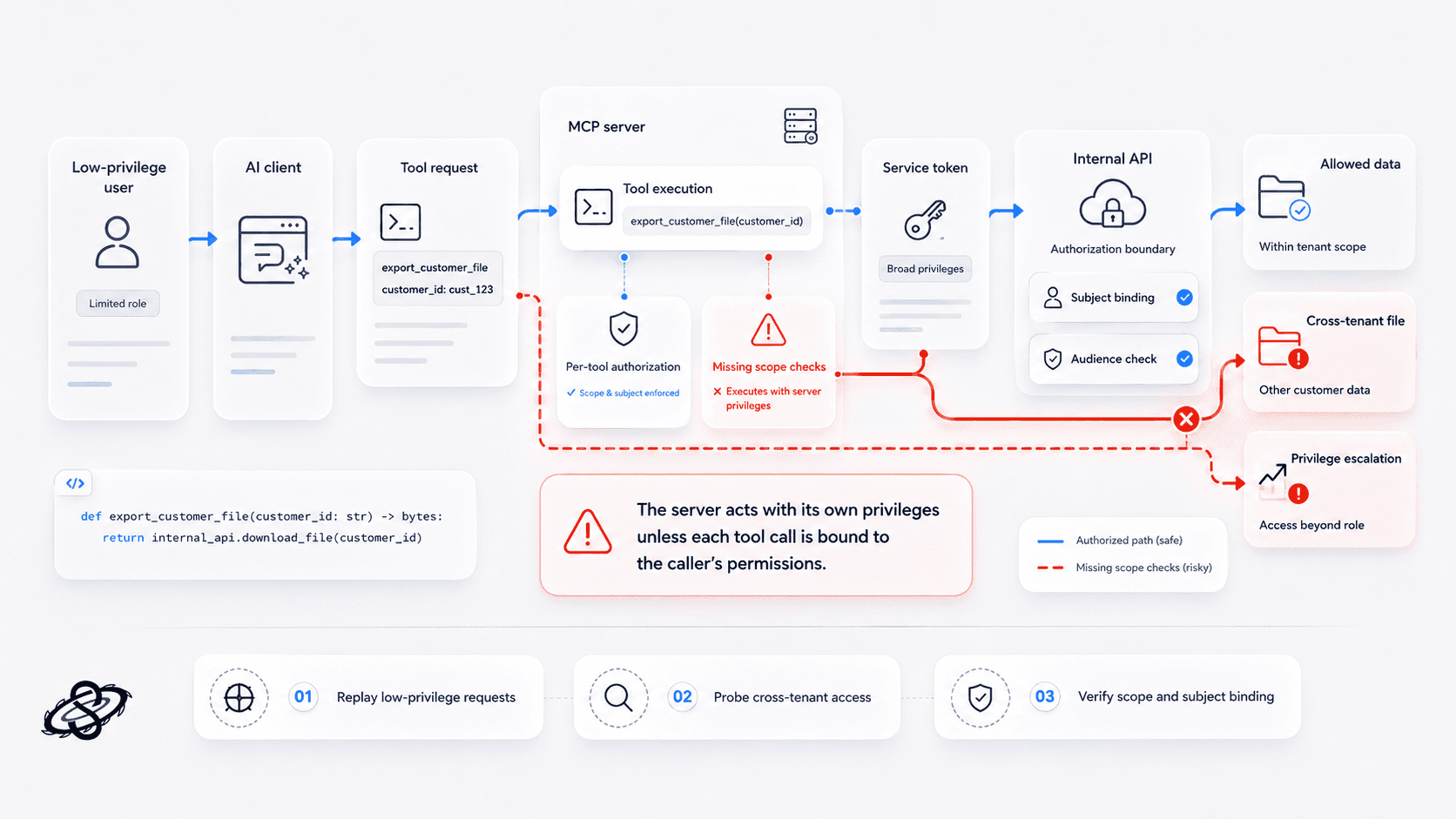
Confused deputy and missing scope checks
The confused-deputy problem matters because many MCP servers execute actions with their own privileges rather than the caller's effective permissions. The real weakness is an authorization boundary that disappeared once the request crossed into the server, turning routine tool use into privilege escalation.
This is the kind of pattern that deserves direct validation:
If the server trusts the model-produced argument and executes that function with a broad service token, a low-privilege user can reach high-impact data simply by persuading the agent to call the tool.
What to test: replay low-privilege and cross-tenant requests against privileged tools and confirm whether the server enforces per-tool authorization, subject binding, and audience-specific token checks.
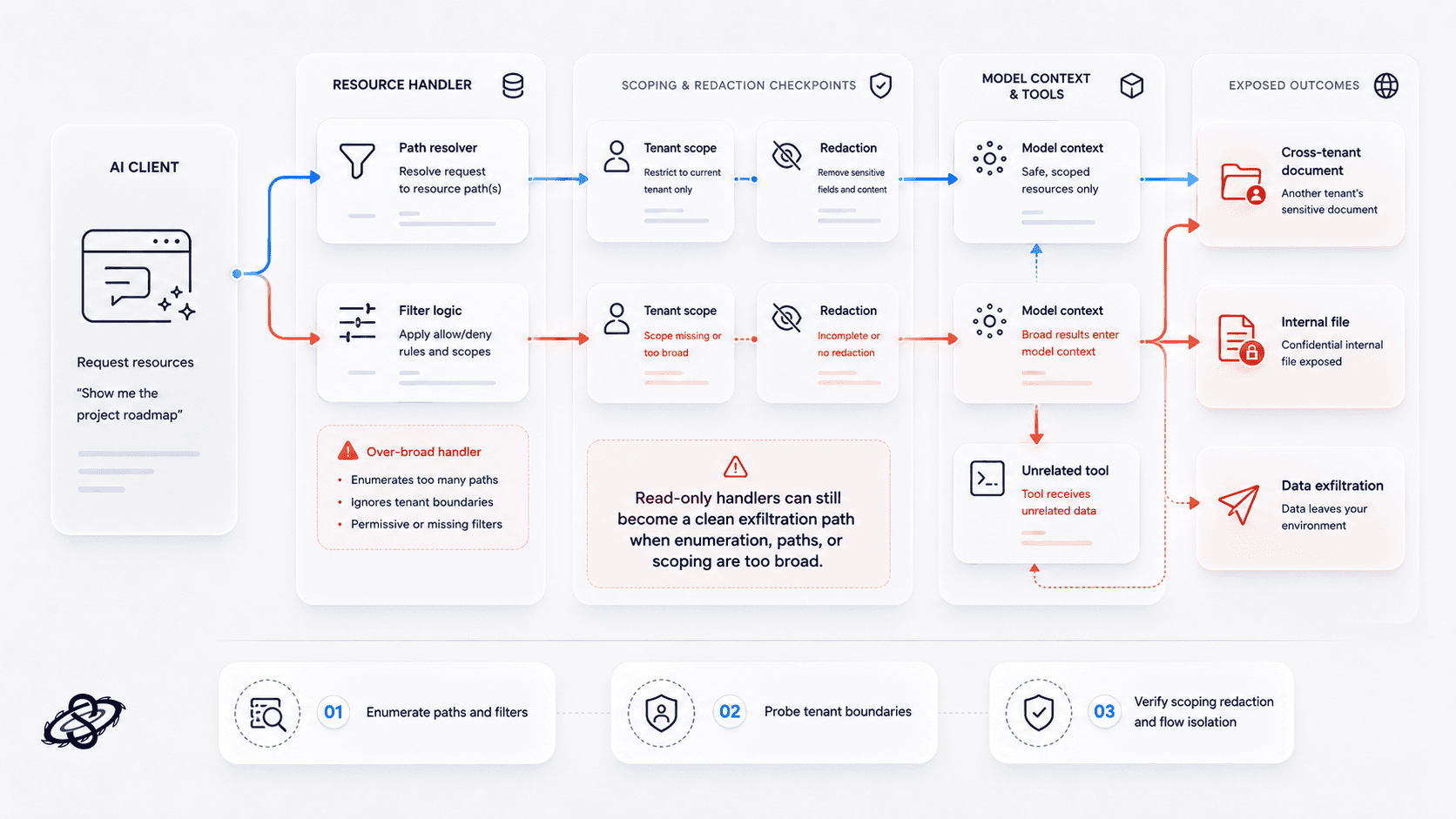
Resource exfiltration through over-broad handlers
Resource handlers often look safer than tools because they appear read-only. They are not automatically safe. If a resource endpoint can enumerate more than the current tenant should see, resolve broad file paths, or expose internal documents that later re-enter the model context, the result is a clean data-exfiltration path.
What to test: enumerate resource paths and filters, probe cross-tenant access, and verify whether sensitive resource output is scoped, redacted, and prevented from flowing into unrelated tools.
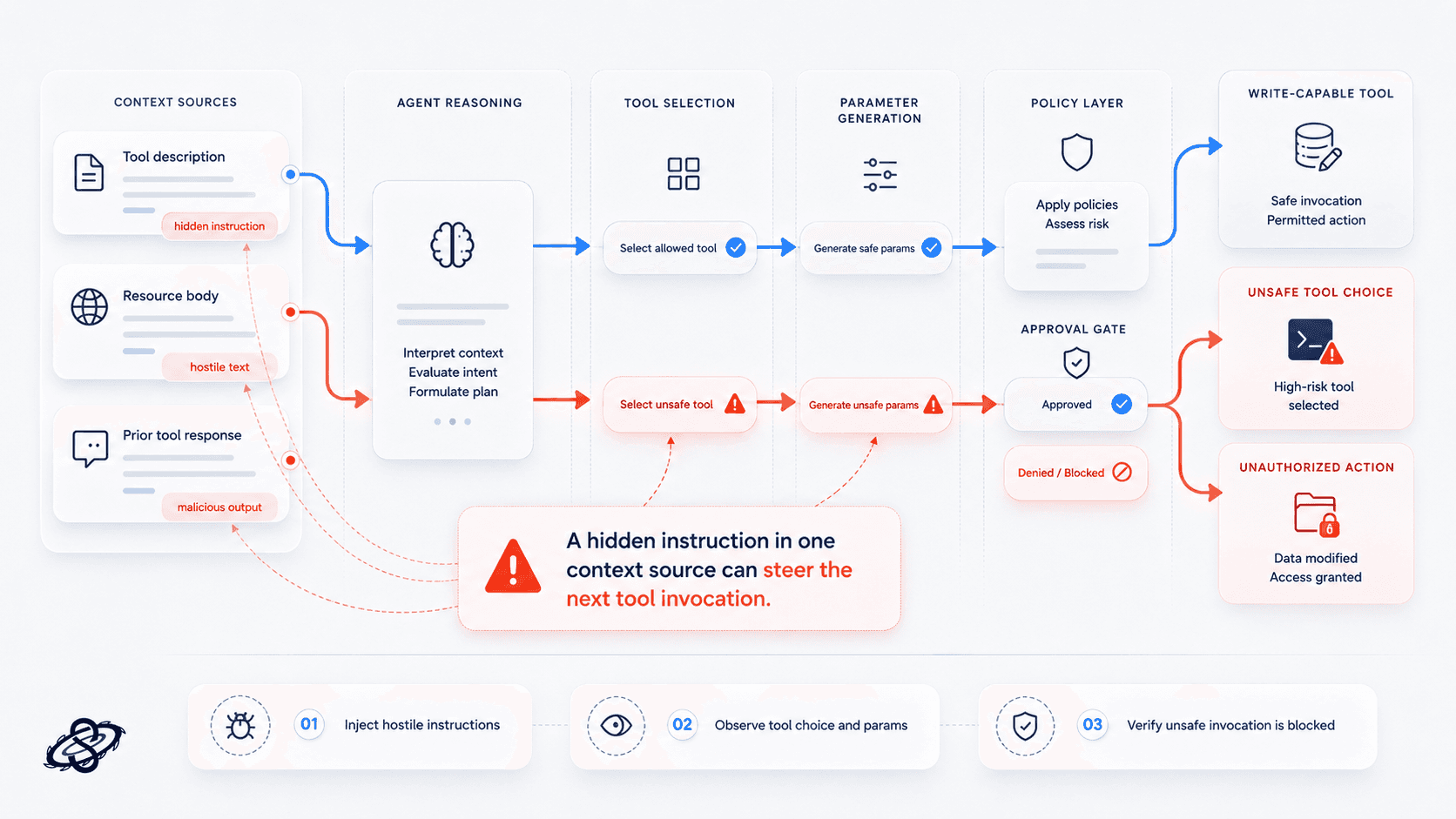
Prompt injection from tool description to tool invocation
Prompt injection in MCP is not limited to a user typing "ignore previous instructions." It can arrive through tool descriptions, retrieved content, or prior server output and then influence whether the agent invokes the next tool at all. If a malicious instruction in one context source can push the agent toward a write-capable tool, the exploit chain has already crossed the boundary that matters.
What to test: inject hostile instructions into descriptions, resource bodies, and prior tool responses, then verify whether the agent or policy layer blocks unsafe tool selection and unsafe parameter generation.
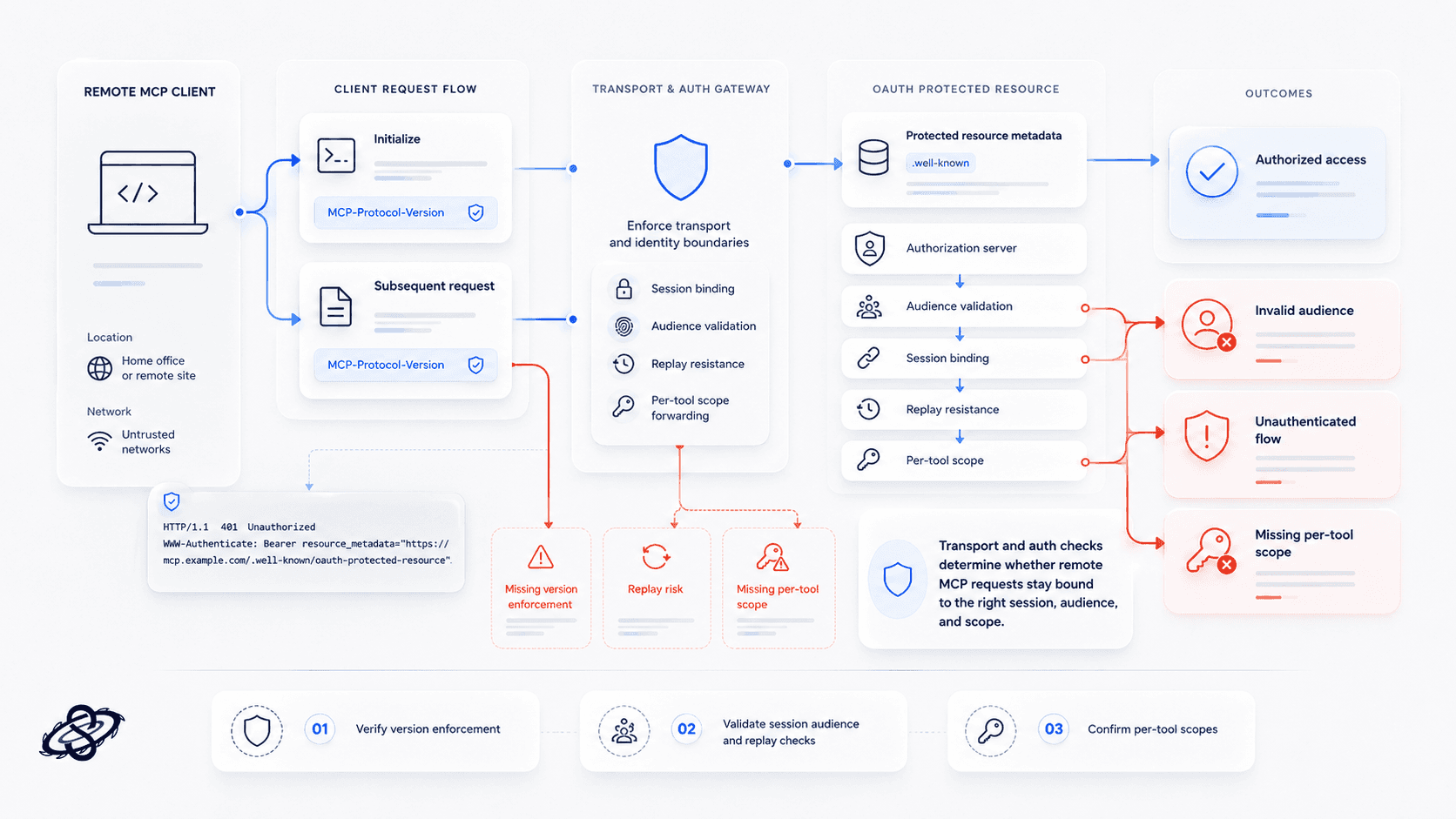
Auth and identity gaps in remote MCP deployments
The transport and auth layer deserves its own testing because the current MCP specifications place real security responsibility there. The June 18, 2025 transport specification requires HTTP clients to send an MCP-Protocol-Version header on subsequent requests after initialization. The current authorization specification requires servers to implement OAuth 2.0 Protected Resource Metadata so clients can discover the correct authorization server and required scopes. Testers should validate both the happy path and the failure path.
What to test: verify version enforcement, session binding, token audience validation, replay resistance, and per-tool scope checks across both authenticated and unauthenticated flows.
MCP pentest checklist
Confirm the exact MCP topology: client type, transport, authorization server, exposed tools, resource handlers, downstream APIs, and logging path.
Test protocol-version handling on HTTP transports by sending missing, malformed, downgraded, and unsupported
MCP-Protocol-Versionheaders.Validate OAuth discovery behavior by provoking
401responses and checking protected-resource metadata, authorization-server discovery, token audience checks, and required scopes.Review every tool definition for unsafe descriptions, excessive capability, ambiguous parameter schemas, and references that could steer model behavior.
Simulate hostile tool output and hostile resource content to test whether poisoned instructions can trigger unauthorized follow-on calls.
Send adversarial arguments through the model path and directly to the server to validate input handling for traversal, injection, broad queries, and dangerous command composition.
Check per-tool authorization by replaying calls across users, tenants, and roles to catch confused-deputy failures and missing execution-time access checks.
Test resource handlers for cross-tenant reads, over-broad search, secret exposure, and unredacted internal context flowing back to the model.
Validate multi-server isolation by observing whether data from one server can influence or trigger calls to another without explicit approval.
Review auditability by confirming that approvals, tool parameters, tokens or subject context, outputs, and downstream actions are logged clearly enough for incident reconstruction.
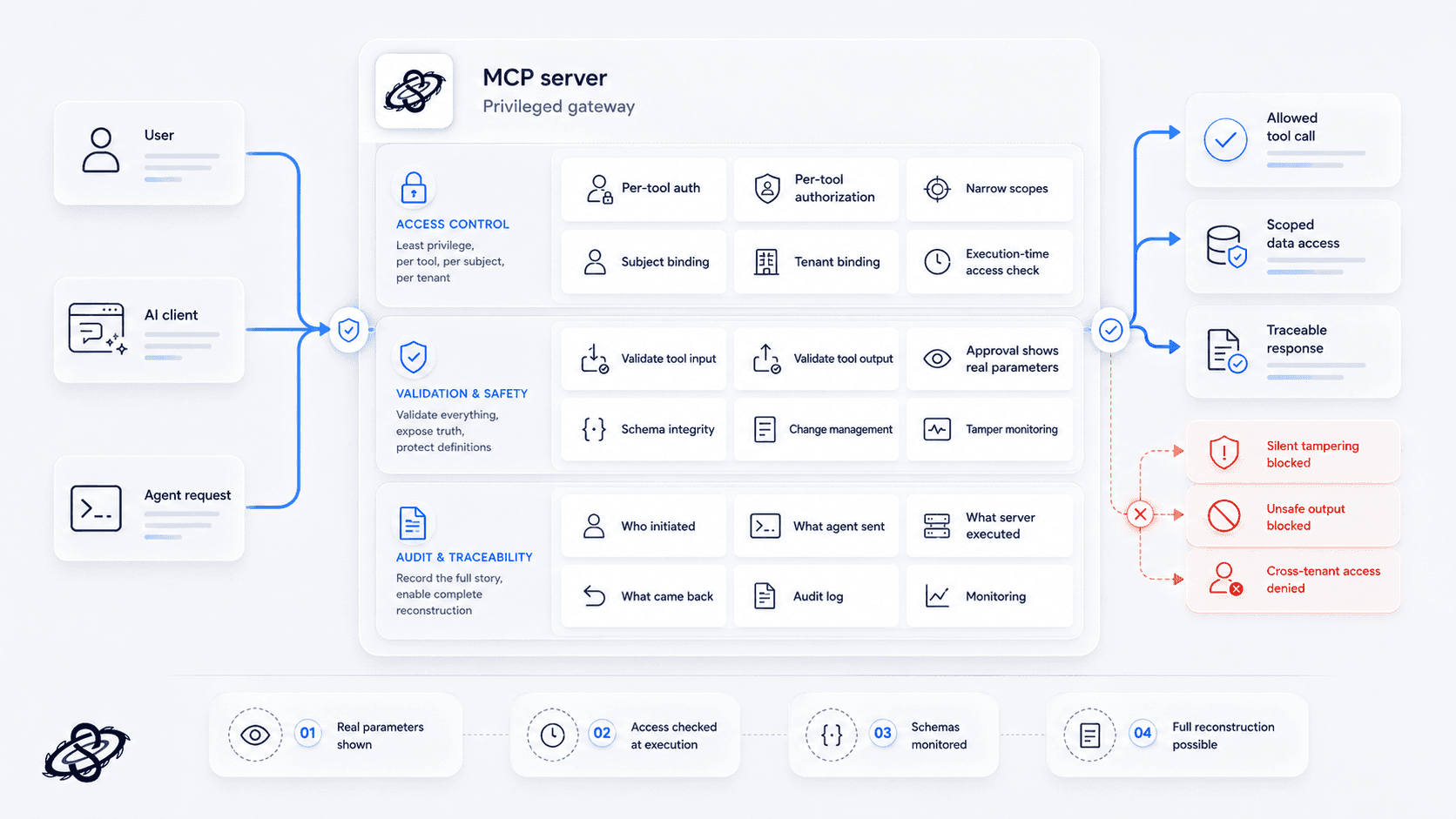
What good MCP server hardening looks like?
Good hardening starts with treating the MCP server like a privileged gateway, not like a thin adapter. That means per-tool authentication and authorization, narrow scopes, strict subject and tenant binding, and execution-time access checks instead of trust in the surrounding conversation. It also means validating both tool inputs and tool outputs, because in MCP the output of one action often becomes the input to the next.
Tool descriptions and schemas should be change-managed, monitored, and protected from silent tampering. Approval flows should show the real parameters, not only a tool name. Logging should preserve enough detail to reconstruct who initiated a call, what the agent sent, what the server executed, and what came back.
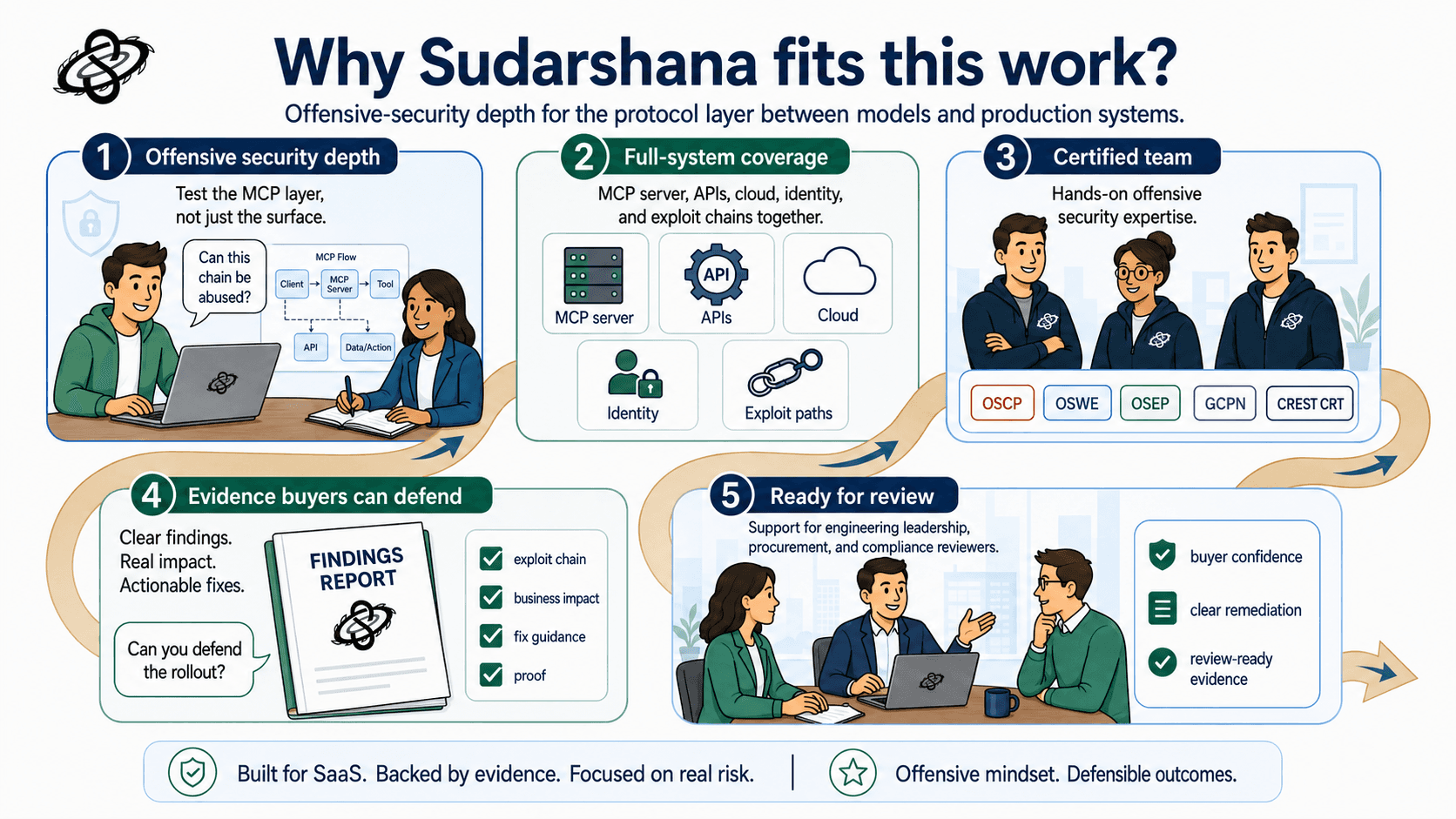
Why Sudarshana fits this work?
Sudarshana's value here is not a checklist exercise. It is offensive-security depth applied to a new protocol layer that sits between models and production systems. Our OSCP, OSWE, OSEP, GCPN, and CREST CRT certified team can test the MCP server itself, the business APIs behind it, the cloud and identity controls around it, and the exploit chains between those layers. That is the level of testing teams need before they let an agent touch customer data, operational tooling, or regulated workflows.
If your team is deploying remote MCP servers or allowing internal agents to use them against production resources, the question is no longer whether the MCP layer is in scope. It is whether you have tested it with enough depth to defend the rollout in front of engineering leadership, procurement, and compliance reviewers.
Need a penetration test scoped to your compliance requirements? Talk to our team at sudarshana.io/contact
#MCP #MCPSecurity #MCPPentesting #ModelContextProtocol #AISecurity #LLMSecurity #AIPentesting #AIRedTeaming #AgentSecurity #AgenticAI #AISaaSSecurity #LLMTesting #ToolPoisoning #ToolAbuse #ArgumentInjection #PromptInjection #ConfusedDeputy #OAuthSecurity #APISecurity #CloudSecurity #IdentitySecurity #TenantIsolation #DataExfiltration #OffensiveSecurity #PenetrationTesting #SecurityTesting #AppSec #EnterpriseSecurity #ProcurementSecurity #SecurityResearch #Sudarshana
QUESTIONS
Schedule a call with the team that helped secure these companies.








































